
همه چیز در مورد داده کاوی با پایتون
امروزه دانستن علم داده کاوی و داده کاوی با پایتون به دلیل حجم بالای داده ها بسیار ضروری می باشد و دولت ها و سازمان ها برای افزایش کارایی خود نیز به اهمیت آن پی برده اند.

در حال حاضر یادگیری زبان برنامه نویسی پایتون یکی از محبوب ترین و پرطرفدارترین مهارت ها در دنیا محسوب می شود و در اکثر فرصت های شغلی مربوط به علوم داده، تسلط به کتابخانه های مختلف پایتون یک امر مهم به شمار می آید.
در واقع می توان گفت که یکی از زبان هایی می باشد که در علم داده کاوی بسیار کاربرد دارد زیرا این زبان به دلیل چند منظوره و سادگی آن مورد استفاده همه افراد قرار گرفته است و همچنین این زبان با داشتن کتابخانه های مختلف موجب شده است که اکثر برنامه نویسان از این زبان استفاده کنند. لذا در این مقاله قصد داریم به طور کامل به شرح داده کاوی با پایتون بپردازیم.
مقاله پییشنهادی : برنامه نویسی اندروید با پایتون
لازم است بدانید که در دوره های آموزش داده کاوی با پایتون سعی می شود تمامی روش ها و مراحل داده کاوی با پایتون به صورت مرحله به مرحله برای پروژه های واقعی توضیح داده شود. همچنین برای افرادی که با پایتون آشنایی ندارند به طور مختصر این زبان آموزش داده می شود و نکات مهم برای کسب آمادگی جهت تحلیل داده با پایتون شرح داده می شود.

چرا داده کاوی با پایتون
متخصصان علوم داده جهت حل مسائل پیچیده خود در زمینه های مختلف نیاز دارند که با یک زبان برنامه نویسی قدرتمند آشنا باشند. از این رو زبان پایتون به دلیل داشتن کتابخانه های گسترده و به روز در زمینه علوم داده توانسته است به جایگاه خوبی بین متخصصان این حوزه دست پیدا کند. چرا پیاده سازی داده کاوی با پایتون مورد توجه قرار گرفته است:
- ساده بودن پایتون
- وجود کتابخانه های متنوع و زیاد در زبان پایتون
- پرکاربرد بودن زبان برنامه نویسی پایتون در حوزه داده کاوی
- قابلیت پیاده سازی و استفاده از آن در انواع سیستم عامل ها
مزایای داده کاوی با پایتون
از جمله مزایای داده کاوی می توان به موارد زیر نام برد:
- وارد کردن انواع داده ها با فرمت های مختلف را می توان یکی از مزایای داده کاوی با پایتون دانست.
- قابلیت پردازش داده با حجم زیاد یکی از مزایای داده کاوی با پایتون می باشد.
- یکی از مزایای داده کاوی با پایتون، تحلیل های آماری هم به صورت ساده و هم به صورت پیشرفته است.
- پیش پردازش داده از جمله مزایای داده کاوی با پایتون می باشد .
- از دیگر مزایای داده کاوی با پایتون تصویر سازی داده ها است.
- از دیگر مزایای داده کاوی با پایتون پیاده سازی الگوریتم های Machine learning می باشد.
- ماتریس Confusionو ارزیابی مدل از دیگر مزایای داده کاوی با پایتون می باشد.

شرکت کنندگان دوره داده کاوی با پایتون چه کسانی هستند؟
شرکت کنندگان دوره داده کاوی با پایتون، فارغ التحصیلان مقاطع کارشناسی ارشد و دکترا در رشته های مهندسی هسته ای، صنایع، هوش مصنوعی، کامپیوتر گرایش نرم افزار، اتوماسیون و مدیریت فناوری اطلاعات می باشد که در زمینه های مختلف از قبیل مدیریت پروژه های برنامه نویسی، داده کاوی، برنامه نویسی تحت وب، طراحی و تحلیل سیستم های بانکی، مدیریت فرایندهای کسب و کار و برنامه ریزی فعالیت می نمایند.
ویدیو پییشنهادی : آموزش پایتون جادی
دوره آشنایی با داده کاوی با پایتون برای چه افرادی مناسب می باشد؟
- افرادی که قصد دارند در مدت زمان کمی با یکی از مهمترین ابزارهای داده کاوی آشنا شوند و داده های مشتریان خود را تحلیل کنند.
- دوره داده کاوی با پایتون برای مدیران فروش و بازاریاب ها نیز مناسب می باشد که قصد دارند داده های مشتریان خود را تحلیل کنند.
- افراد کارشناسی که در زمینه مدیریت ارتباط با مشتری فعالیت می کنند و قصد یادگیری روش های تحلیل داده های مشتریان را دارند.
- دانشجویان و فارغ التحصیلانی که قصد دارند با استفاده از علم داده کاوی به عنوان بخشی از آماده کردن خود جهت پیدا کردن شغل در حوزه مدیریت ارتباط با مشتری و داده کاوی فعالیت کنند.

کتابخانه های مورد نیاز
همان طور که قبلا گفتیم برای انجام عملیات داده کاوی با پایتون باید با کتابخانه های مورد نیاز در داده کاوی با پایتون آشنا شویم تا با استفاده از آنها بتوانیم کدها را اجرا کنیم. از جمله کتابخانه های مورد نیاز در داده کاوی با پایتون می توان به موارد زیر اشاره کرد:
کتابخانه Numpy
این کتابخانه در بیشتر محاسبات علمی در زبان برنامه نویسی پایتون مورد استفاده قرار می گیرد. در واقع این کتابخانه ابزارهایی برای یکپارچه سازی C، C++ و کدهای فرترن را فراهم می کند و همچنین در محاسبات تبدیل فوریه، جبر خطی و اعداد تصادفی کاربرد دارد.
کتابخانه Numpy عملکردهای از قبل تعیین شده از روتین های عددی در اختیار برنامه نویس قرار می دهد.

کتابخانه Scipy
یک کتابخانه متن باز می باشد که در زمینه ریاضیات، مهندسی و علمی مورد استفاده قرار می گیرد. کاربرد ماژول های کتابخانه Scipy در زمینه بهینه سازی، یکپارچه سازی، آمار، جبر خطی،سری فوریه و همچنین در معادلات دیفرانسیل است. با استفاده از این کتابخانه می توان به آرایه های n بعدی دسترسی پیدا کرد.
کتابخانه Matplotlib
یکی از کتابخانه های دو بعدی می باشد که برای رسم نمودار در پایتون مورد استفاده قرار می گیرد. این کتابخانه این امکان را برای برنامه نویس فراهم می کند که به سرعت داده های خود را به شکل نمودار و گراف تبدیل کند.
ویدیو پییشنهادی : آموزش رایگان داده کاوی
همچنین از این کتابخانه می توان برای اسکریپت های ساده استفاده کرد. از دیگر کاربردهای این کتابخانه می توان به برنامه های وب سرور، رابط های گرافیکی و lpython اشاره کرد. این کتابخانه بیشتر برای الگوریتم های مشهور یادگیری ماشین می باشد.
کتابخانه Pandas
این کتابخانه امکان ارائه اطلاعات با ساختار سطح بالا برای عملیات ساده و تحلیل داده ها را برای کاربر فراهم می کند.
کتابخانه Gensim
این کتابخانه در مدل سازی موضوعی، اندیس گذاری اسناد و بازیابی مشابهات در مستندات بزرگ کاربرد دارد.
قابل توجه است که برای استفاده از کتابخانه ها در داده کاوی با پایتون باید قبل از شروع کدنویسی آنها را به صورت زیر فراخواند:
<span style="font-size: 16px;">import pandas aspd import matplotlib.pyplot asplt import numpy asnp import scipy.stats asstats import seaborn assns</span> |
مراحل پیاده سازی داده کاوی با پایتون به شرح زیر می باشد:
مرحله اول: آماده سازی داده ها
اولین مرحله جهت پیاده سازی داده کاوی با پایتون، آماده سازی داده ها می باشد که روش های متفاوتی جهت به کار بردن کتابخانه های مختلف با توجه به به نوع داده ها و نتیجه مورد نظر وجود دارد. آماده سازی داده برای الگوریتم های معروف machine learning، یکی از ابزارهای مهم داده کاوی با پایتون به شمار می آید که دارای کاربردهای زیر است:
- آنالیز کردن داده ها
- مدیریت داده های تکمیل نشده
- نرمال سازی داده ها
- دسته بندی کردن داده ها به انواع مختلف
- معرفی داده به برنامه از طریق دستور
به عنوان مثال داده های یک نمونه کار شامل 50 نمونه از 3 مدل گل مورد ارزیابی قرار می گیرد. داده های دریافتی دارای 5 ردیف هستند که 4 ردیف اول مقادیر و ردیف آخر کلاس نمونه است و دستور آن به صورت زیر است:
<span style="font-size: 16px;">import urllib2 url='http://aima.cs.berkeley.edu/data/iris.csv' u=urllib2.urlopen(url) localFile=open('iris.csv','w') localFile.write(u.read()) numpy import genfromtxt,zeros # read the first 4 columns data=genfromtxt('iris.csv',delimiter=',',usecols=(0,1,2,3)) # read the fifth column target=genfromtxt('iris.csv',delimiter=',',usecols=(4),dtype=str) print set(target)# build a collection of unique elements set(['setosa','versicolor','virginica'])</span> |
مرحله دوم: تصویرسازی داده ها
برای این که بفهمیم داده ها چه اطلاعاتی را در اختیار ما قرار می دهد و نحوه ساختار آنها یک امر مهم در داده کاوی می باشد که به کمک تصویرسازی و به صورت گرافیکی می توان این اطلاعات را به دست آورد.
مقاله پییشنهادی : معرفی کامل داده کاوی
استفاده از نمودارها با ما کمک می کند که مقادیر دو داده های مختلف را به صورت گرافیکی باهم مقایسه کرد. بنابراین یکی از مراحل پیاده سازی داده کاوی با پایتون، تصویر سازی داده ها می باشد. به عنوان مثال با نوشتن دستور زیر گرافی رسم می شود:
<span style="font-size: 16px;">import plot,show plot(data[target=='setosa',0],data[target=='setosa',2],'bo') plot(data[target=='versicolor',0],data[target=='versicolor',2],'ro') plot(data[target=='virginica',0],data[target=='virginica',2],'go') show()</span> |
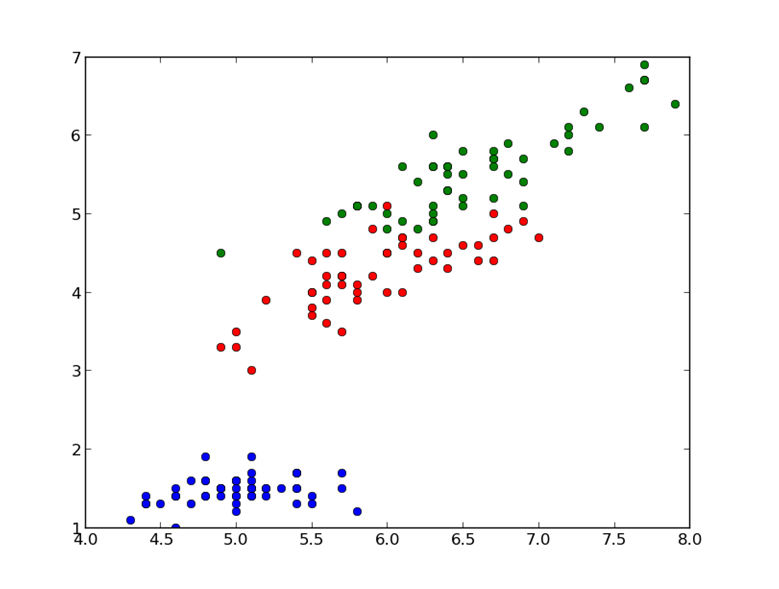
گراف فوق شامل 150 نقطه و 3 رنگ که بیانگر کلاس ها است، می باشد.
مرحله سوم: طبقه بندی و رگرسیون (Classification and Regression)
درک این مرحله از مراحل پیاده سازی داده کاوی با پایتون نسبت به سایر مراحل قابل درک تر است. در این مرحله ابتدا داده ها را طبقه بندی می کنیم تا بتوانیم مدلی از روی آنها بسازیم که بتوان از این مدل برای پیش بینی طبقه هایی که معلوم نیستند استفاده کرد. شکل زیر یک نمونه کد طبقه بندی در پایتون می باشد:
لازم است بدانید که مرحله طبقه بندی داده ها از مراحل پیاده سازی داده کاوی با پایتون دارای الگوریتم های زیر می باشد:
- درخت تصمیم (Decision Tree)
- بیز ساده (Naïve Bayes)
- شبکه عصبی پرسپترون چند لایه (Multi Layer Perceptron)
- ماشین بردار پشتیبان (Support Vector Machine)
- نزدیکترین همسایگی (K-Nearest Neighbors)
- روش های یادگیری تجمعی (Ensemble Learning)
لازم است بدانید که یکی از الگوریتم های طبقه بندی داده ها، الگوریتم رگرسیون می باشد که روابط بین داده ها و مدل سازی آنها را بررسی می کند و هدف از استفاده از این الگوریتم این است پیش بینی مقدار یک متغیر پیوسته بر طبق مقادیر دیگر متغیرها می باشد که دارای 2 نوع می باشد:
- رگرسیون خطی (Linear Regression)
- رگرسیون لجستیک (Logistic Regression)

مرحله سوم: خوشه بندی (clustering)
این مرحله از مراحل پیاده سازی داده کاوی با پایتون به صورت اتوماتیک انجام می شود که داده ها را به دسته هایی که دارای اعضای مشابه هستند، تقسیم می کند. شباهت در نظر گرفته شده بسته به کاربرد و نتیجه و نوع تحلیل متغیر می باشد به طوری که در هر دسته ها اعضا با هم مشابه هستند و با دسته های دیگر نامشابه.
هدف از انجام این مرحله از مراحل پیاده سازی داده کاوی با پایتون این است که مجموعه مشابه از موارد در بین داده های ورودی را پیدا کنیم که تعداد خوشه ها معیار و ملاک خوشه بندی می باشد و این که کدام خوشه مطلوب تر است بسته به الگوریتم و هدف فرد است.
مقاله پییشنهادی : آموزش یادگیری ماشین لرنینگ با پایتون
تفاوت بین مرحله خوشه بندی و طبقه بندی این است که خوشه بندی برای توصیف داده هاست ولی طبقه بندی برای ایجاد یک مدل پیش گویی کننده است که توانایی طبقه بندی داده ها را داشته باشد و هم این که بتوان پیش بینی کرد که داده تازه وارد شده متعلق به کدام طبقه می باشد. در مرحله خوشه بندی دو الگوریتم مورد استفاده قرار می گیرد:
- الگوریتم K-means
- الگوریتم DBSCAN
مرحله چهارم: کشف الگوهای مکرر و قواعد انجمنی
مرحله چهارم از مراحل پیاده سازی داده کاوی با پایتون، کشف الگوهای مکرر و قواعد انجمنی است. هدف از قواعد انجمنی، یافتن مواردی می باشد که به صورت معناداری با هم همبستگی دارند.
به عنوان مثال می توان تراکنش کالاهای خریداری شده را بررسی کرد تا ترکیبی از کالاهایی را که معمولا با هم خریداری می شوند، به دست آورد.
برای رسیدن به این هدف بایستی به این سوال پاسخ داد که اگر دسته ای از موارد در یک تراکنش باشند کدام مورد به نظر می رسد که در تراکنشی یکسان با آنها قرار داشته اند؟ بنابراین تابعی که این قانون را از داده ها استخراج می کند، تابع انجمنی نامیده می شود و بهترین میزان سنجش همبستگی ضریب همبستگی پیرسون است که آن را می توان از تقسیم کواریانس دو متغیر به دست آورد. دستور زیر به وضوح روش محاسبه را بیان می کند:
<span style="font-size: 16px;">from numpy import corrcoef corr=corrcoef(data.T)# .T gives the transpose print corr</span> |
حاصل این دستور یک ماتریس شامل همبستگی ها می باشد که ردیف های آن بیانگر متغیرها و ستون های آن مشاهدات هستند و هر عضو از آن بیانگر همبستگی دو متغیر است. لازم است بدانید که زمانی همبستگی مثبت می شود که دو متغیر با هم رشد کند و زمانی آن منفی می شود که یکی رشد کند و دیگری کاهش یابد. اما زمانی که تعداد متغیرها بالا است می توان نموداری با دستور زیر رسم کرد:
<span style="font-size: 16px;">from pylab import pcolor,colorbar,xticks,yticks from numpy import arrange pcolor(corr) colorbar()# add # arranging the names of the variables on the axis xticks(arange(0.5,4.5),['sepal length','sepal width','petal length','petal width'],rotation=-20) yticks(arange(0.5,4.5),['sepal length','sepal width','petal length','petal width'],rotation=-20) show()</span> |
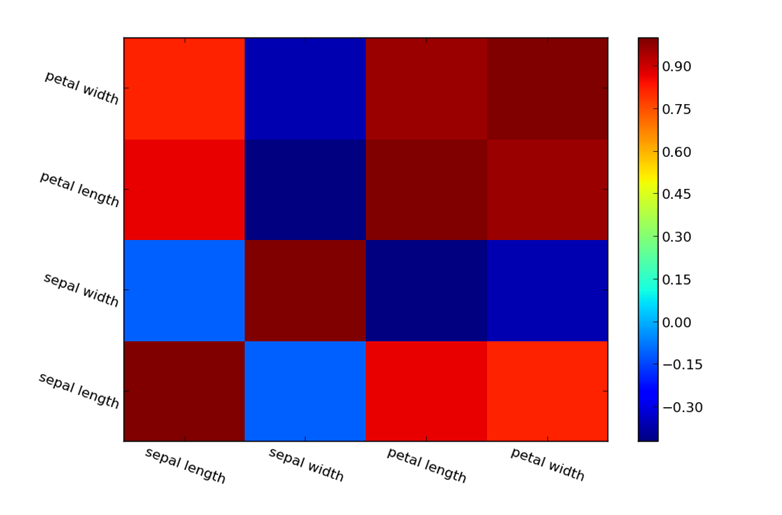
حاصل دستور فوق نمودار زیر می باشد:
الگوریتم های قواعد انجمنی
- الگوریتم Apriori
- الگوریتم Fp-frowth
مرحله پنجم: روش های ارزیابی مدل ها
مرحله آخر از مراحل پیاده سازی داده کاوی با پایتون، روش های ارزیابی مدل می باشد که از جمله این روش ها می توان به موارد زیر اشاره کرد:
- ارزیابی مدل های رده بندی
- ارزیابی مدل های رگرسیون
- ارزیابی مدل های خوشه بندی
- ارزیابی الگوهای پرتکرار و قواعد انجمنی
امید است این مقاله با عنوان آموزش داده کاوی با پایتون برای شما مفید واقع گردد.
منابع
- https: // www.dayche.com/academy/education/courses/data-mining-in-python/
- https: // www.placabi.com/resources/news/item/209-data-mining-and-python-aug-2017.html

چند سالی میشه که در زمینه سئو و دیجیتال مارکتینگ در حال فعالیت هستم. به موسیقی و فلسفه علاقه ی خاصی دارم و بیشتر زمان رو صرف مطالعه و نوازندگی می کنم.